In the Wild Deployment
East Asia Library Setting
The East Asia Library is a large library with varied shelf heights, lengths, backgrounds, and lighting conditions. We consider the task of scanning bookshelves for inventory management, a time-consuming task for librarians.

We visualize a representative shelf from each deployment session to highlight the diversity of the library.
Challenges with Reading Books

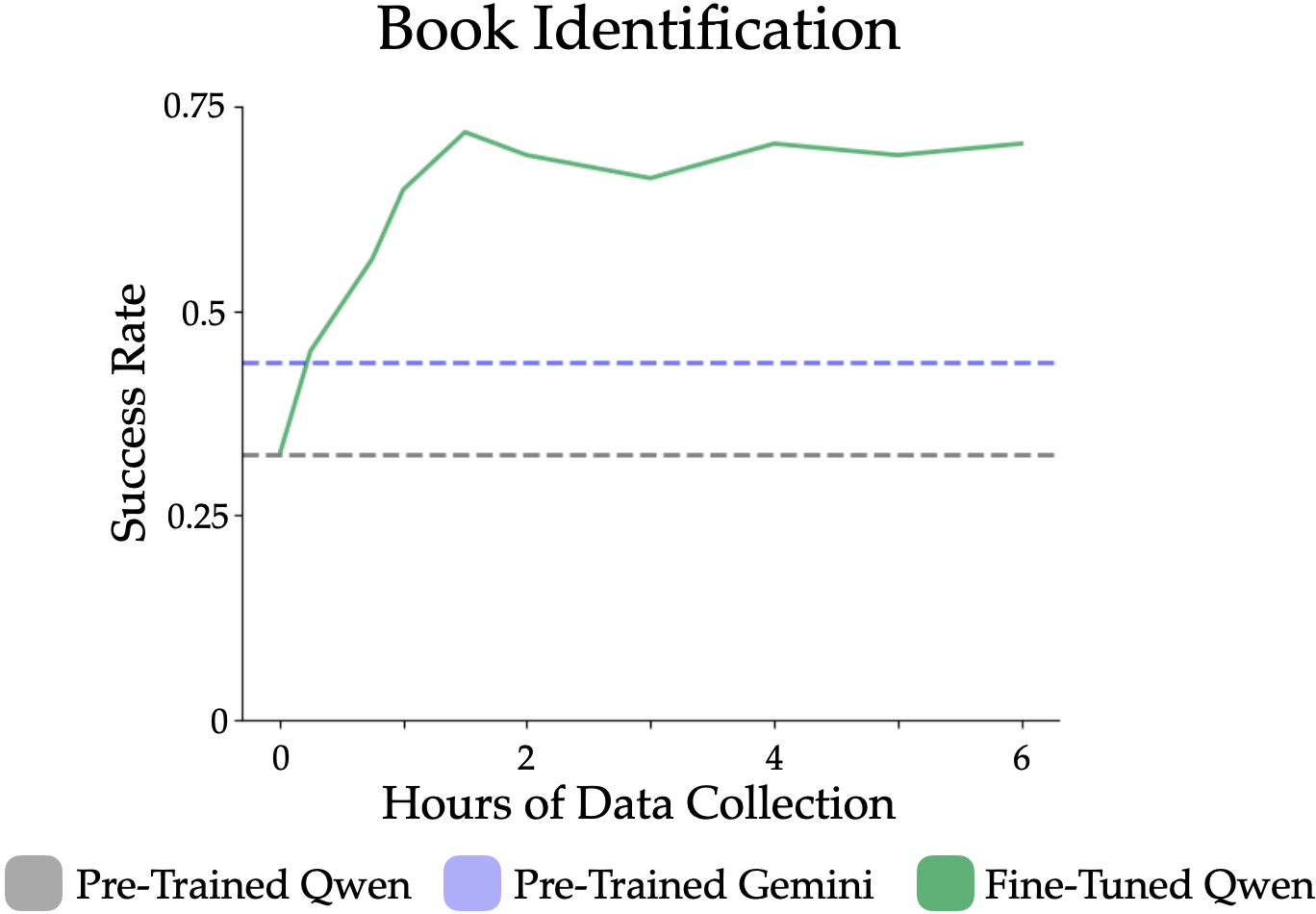
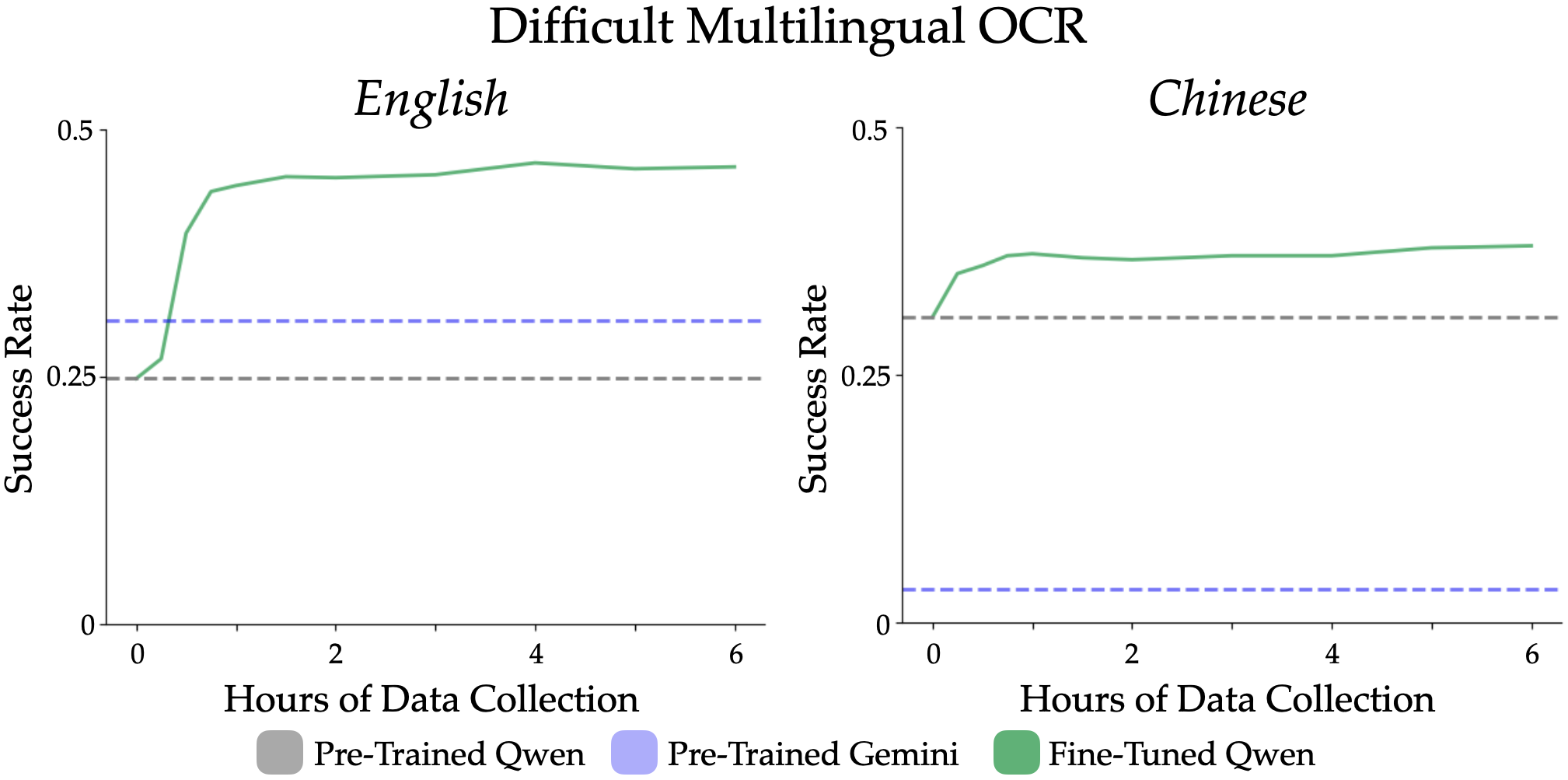
Reading and identifying books in the wild is challenging due to damaged book labels, occlusions, and fading and aging on books -- these cases are often underrepresented in the curated, internet data used to pre-train foundation models. The East Asia Lbrary holds another challenge: all its books are in Chinese, Japanese, or Korean. Existing foundation models struggle with these languages due to the heavy bias towards English in internet data. Scanford addresses these challenges by fine-tuning the VLM on real-world data collected from the East Asia Library using a mobile manipulator.